
In this article, I want to discuss the use of ELO as an evaluation method for LLMs (Large Language Models). The LLM test portal ChatBot Arena utilizes this approach to rate LLMs. I became aware of this evaluation process behind the ChatBot Arena through Martin Blaha, who had read my article “How are LLM systems tested”.
I would like to thank again for the hint! The approach of the ChatBot Arena and the logic behind it should also not remain unknown.
What is the ChatBot Arena?
The ChatBot Arena is a platform designed to test and compare various language models in realistic scenarios. The models tested include well-known developments such as OpenAI’s GPT-4, Anthropic’s Claude, GPT-3.5-turbo, and specialized models like Vicuna. In addition, other models that pursue various approaches in language modeling are tested in this arena.
The ChatBot Arena uses the ELO rating system to assess the relative capabilities of the different models. This allows a direct comparison of the performance of the various language models under realistic conditions.
Within the ChatBot Arena, two LLMs compete against each other. In the default setting, it is not apparent which LLM is being tested:
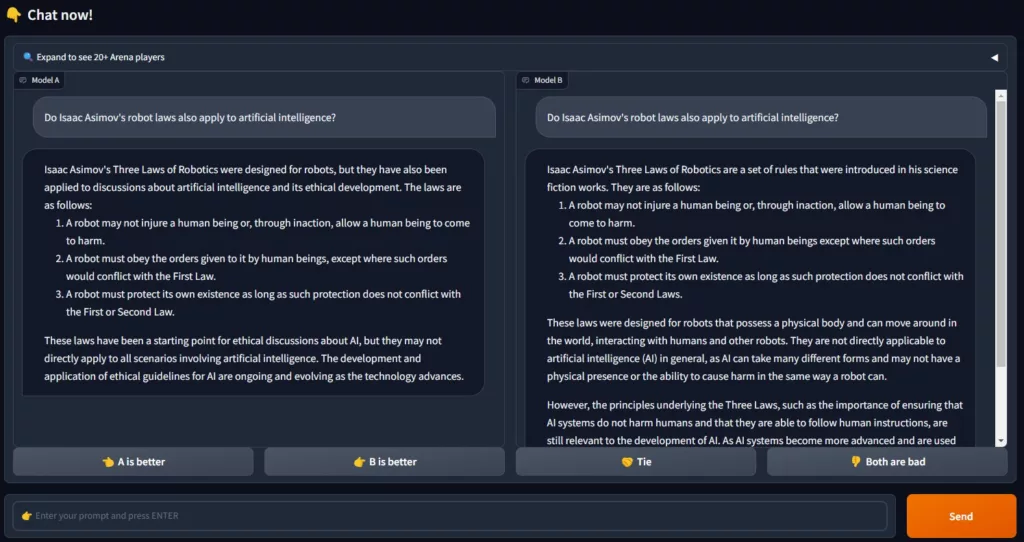
After the user has evaluated the result of the LLMs, it is then also displayed which LLM system was queried:
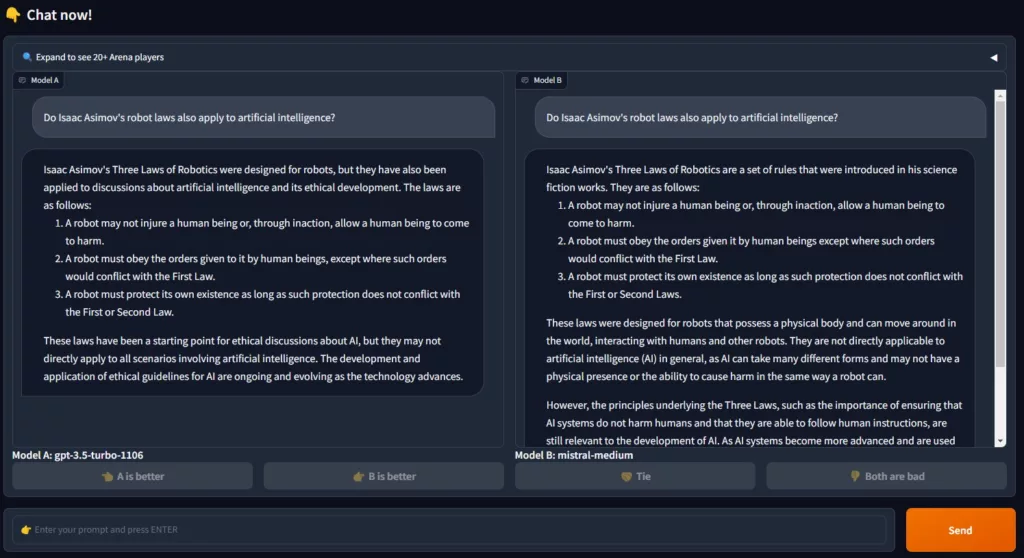
The ratings of the respective systems flow into the ranking of the LLMs. The evaluation system is based on the ELO system.
How does the ELO system work in the ChatBot Arena?
The ELO system is a rating system originally developed for ranking the playing strength of chess players. Designed by physicist Arpad Elo, it is based on a mathematical formula that assesses the relative abilities of players in competitive games or sports. The core idea of the system is that a player’s score is an estimate of his ability. If a player wins, his score increases, and it decreases with a loss. The amount of points gained or lost depends on the expected probability of the outcome, which is derived from the difference in the ELO points of the two players.
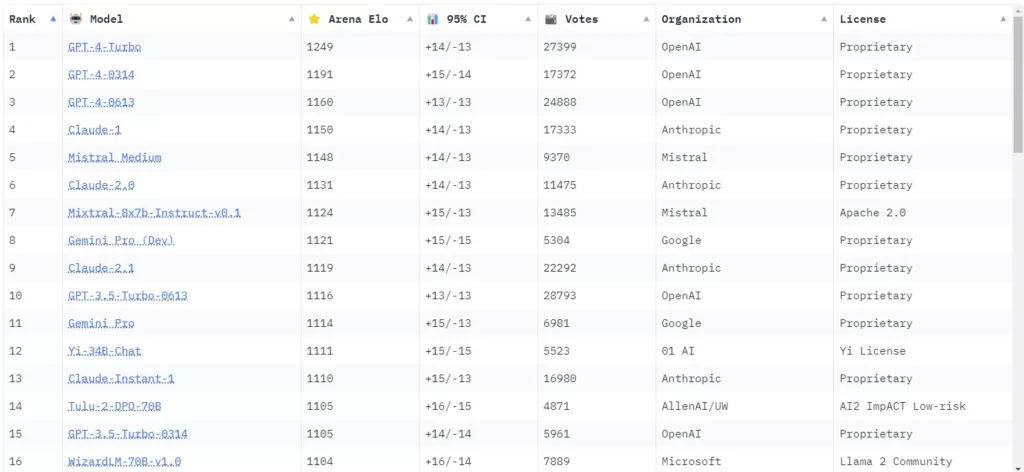
What are the advantages of the ELO system, or the approach of the ChatBot Arena?
The developers of the ChatBot Arena see the following advantages in the use of the ELO system:
- Contextualization in Practice: The “Chatbot Arena” is a platform that simulates actual use cases of LLMs. This approach gives the ELO system a realistic component that goes beyond theoretical or isolated tests.
- User-Centered Evaluation: Unlike traditional benchmarks, which often rely on predefined tasks, the Chatbot Arena uses the judgments and interactions of real users. This approach better reflects how LLMs might perform in real-world application scenarios.
- Dynamic and Incremental Evaluation: The ability to assess new models with a relatively small number of trials and provide a unique ranking for all models, as described in the article, demonstrates the flexibility of the ELO system in a rapidly evolving field like LLMs.
- Diversity of Models and Tasks: The inclusion of a variety of models, including open-source and closed-source models, and evaluation across different languages and task types, significantly expands the application of the ELO system.
- Transparency and Community Participation: The public accessibility of the Chatbot Arena and the invitation to the community to participate in this benchmarking process promote a transparent and collaborative approach to evaluating LLMs.
- Complexity of Evaluating Open Responses: The challenge of effectively evaluating LLM assistants, especially with open-ended questions that cannot be answered with a standardized response. This underscores the importance of a system like ELO, which allows for differentiated and nuanced evaluation.
Advantages of ELO for Practice and in Relation to LLMs
This application of the ELO system emphasizes the need for a flexible and nuanced evaluation method in the rapidly evolving world of LLMs. It shows that such a system not only allows for quantitative comparisons but can also reflect the complexity and diversity of real-world application scenarios. Thus, the ELO system becomes a valuable tool for the continuous assessment and improvement of LLMs.
In practice, the ELO calculation is an iterative process where the ratings of the participants (whether chess players or LLMs) are continuously adjusted after each “game” or interaction based on the actual outcome and the expected result. This process allows for an ongoing and dynamic assessment of the relative abilities of the participants, which is particularly useful in areas where new participants are constantly being added or where performance capabilities change rapidly, as in the case of LLMs.
Of course, this type of evaluation can be subjective and influenced. The advantage of standardized response tests is the examination against a common and defined standard.
Naturally, each of these testing methods (standardized or ELO) has its very sensible area of application.
Further information:
Explanation of the use of ELO as a measurement method at the Large Model Systems Organization (LMSYS Org) – https://lmsys.org/blog/2023-05-03-arena/
The current leaderboard for the area of LLMs of the LMSYS Org can be viewed here: https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard
General note: This text was co-generated with the help of ChatGPT, or technical terms were explained by a GPT.