
In diesem Artikel will ich auf die Nutzung von ELO als Bewertungsmethode für LLMs eingehen. Das LLM-Testportal ChatBot Arena nutzt diesen Ansatz um LLMs zu bewerten. Ich war auf dieses Bewertungsverfahren hinter der ChatBot Arena durch Martin Blaha hingewiesen worden, welcher meinen Artikel „Wie werden LLM-Systeme getestet“ gelesen hatte.
An dieser Stelle noch einmal Danke für den Hinweis! Der Ansatz der ChatBot Arena und die Logik dahinter sollten auch nicht unbekannt bleiben.
Was ist die ChatBot Arena?
Die ChatBot Arena ist eine Plattform, die darauf ausgelegt ist, verschiedene Sprachmodelle in realitätsnahen Szenarien zu testen und zu vergleichen. Zu den getesteten Modellen gehören bekannte Entwicklungen wie OpenAI’s GPT-4, Anthropic’s Claude und GPT-3.5-turbo, sowie spezialisierte Modelle wie Vicuna. Darüber hinaus werden auch andere Modelle, die verschiedene Ansätze in der Sprachmodellierung verfolgen, in dieser Arena getestet.
Die ChatBot Arena nutzt das ELO-Bewertungssystem, um die relativen Fähigkeiten der unterschiedlichen Modelle zu bewerten. Dies ermöglicht einen direkten Vergleich der Leistungsfähigkeit der verschiedenen Sprachmodelle unter realistischen Bedingungen.
Innerhalb der ChatBot Arena treten dabei zwei LLMs gegeneinander an. In der Grundeinstellung ist nicht ersichtlich, welches LLM getestet wird:
Nachdem das Ergebnis der LLMs durch den Benutzter bewertet wurde, wird dann auch angezeigt, welches LLM-System befragt wurde:
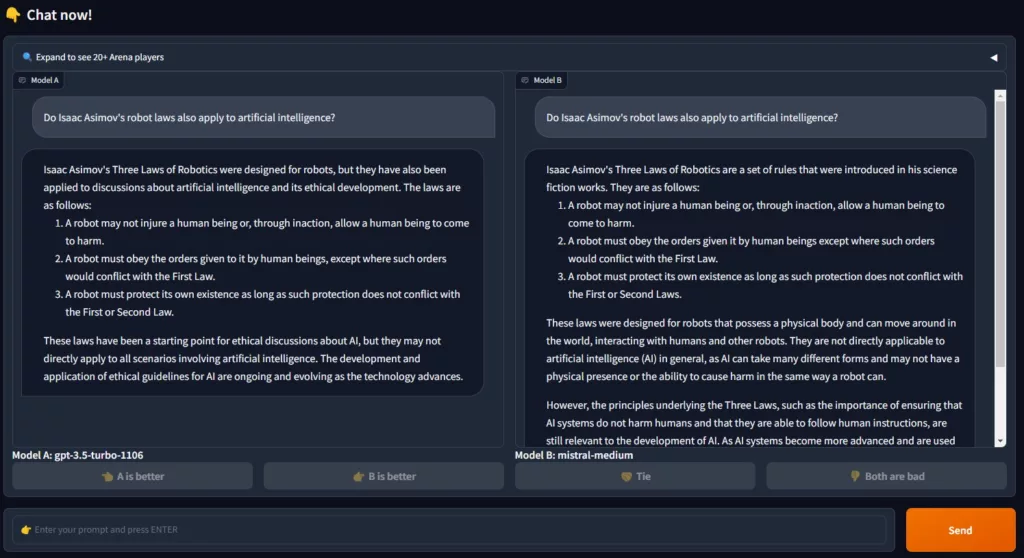
Die Bewertungen der jeweiligen System fließen in das Ranking der LLMs ein. Das Bewertungssystem basiert dabei auf dem ELO-System.
Wie funktioniert das ELO-System in der ChatBot Arena?
Das ELO-System ist ein Bewertungssystem, das ursprünglich für die Einstufung der Spielstärke von Schachspielern entwickelt wurde. Entworfen vom Physiker Arpad Elo, basiert es auf einer mathematischen Formel, die die relativen Fähigkeiten von Spielern in kompetitiven Spielen oder Sportarten bewertet. Im Kern des Systems steht die Idee, dass die Punktezahl eines Spielers eine Schätzung seiner Fähigkeit darstellt. Gewinnt ein Spieler, erhöht sich seine Punktezahl, und bei einer Niederlage sinkt sie. Die Menge der gewonnenen oder verlorenen Punkte hängt von der erwarteten Wahrscheinlichkeit des Ausgangs ab, die sich aus dem Unterschied in den ELO-Punkten der beiden Spieler ergibt.
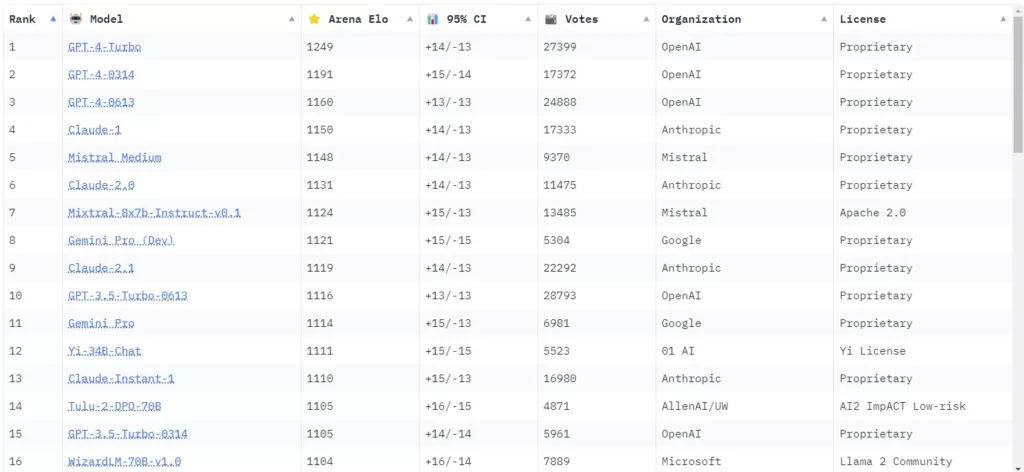
Welche Vorteile bietet das ELO-System, bzw. der Ansatz der ChatBot Arena?
Die Entwickler der ChatBot Arena sehen für den Einsatz des ELO-Systems folgende Vorteile:
- Kontextualisierung in der Praxis: Die „Chatbot Arena“ ist eine Plattform, die tatsächliche Anwendungsfälle von LLMs simuliert. Dieser Ansatz verleiht dem ELO-System eine realitätsnahe Komponente, die über theoretische oder isolierte Tests hinausgeht.
- Benutzerzentrierte Evaluierung: Im Gegensatz zu traditionellen Benchmarks, die oft auf vordefinierten Aufgaben basieren, nutzt die Chatbot Arena die Urteile und Interaktionen echter Benutzer. Dieser Ansatz spiegelt besser wider, wie LLMs in realen Anwendungsszenarien abschneiden könnten.
- Dynamische und inkrementelle Bewertung: Die Möglichkeit, neue Modelle mit einer relativ kleinen Anzahl von Versuchen zu bewerten und eine einzigartige Rangordnung für alle Modelle zu bieten, wie im Artikel beschrieben, zeigt die Flexibilität des ELO-Systems in einem sich schnell entwickelnden Feld wie LLMs.
- Vielfalt der Modelle und Aufgaben: Die Einbeziehung einer Vielzahl von Modellen, darunter Open-Source- und Closed-Source-Modelle, sowie die Bewertung über verschiedene Sprachen und Aufgabentypen hinweg, erweitert die Anwendung des ELO-Systems erheblich.
- Transparenz und Gemeinschaftsbeteiligung: Die öffentliche Zugänglichkeit der Chatbot Arena und die Einladung an die Gemeinschaft, an diesem Benchmarking-Prozess teilzunehmen, fördern eine transparente und kollaborative Herangehensweise an die Bewertung von LLMs.
- Komplexität der Bewertung offener Antworten: Die Herausforderung, LLM-Assistenten effektiv zu bewerten, besonders bei offenen Fragen, die nicht durch eine standardisierte Antwort beantwortet werden können. Dies unterstreicht die Bedeutung eines Systems wie ELO, welches eine differenzierte und nuancierte Bewertung ermöglicht.
Vorteile von ELO für die Praxis und in Bezug auf LLMs
Diese Anwendung des ELO-Systems betont die Notwendigkeit einer flexiblen und nuancierten Bewertungsmethode in der sich schnell entwickelnden Welt der LLMs. Sie zeigt, dass ein solches System nicht nur quantitative Vergleiche ermöglicht, sondern auch die Komplexität und Vielfalt realer Anwendungsszenarien abbilden kann. Dadurch wird das ELO-System zu einem wertvollen Werkzeug für die kontinuierliche Bewertung und Verbesserung von LLMs.
In der Praxis ist die ELO-Berechnung ein iterativer Prozess, bei dem die Bewertungen der Teilnehmer (sei es Schachspieler oder LLMs) nach jedem „Spiel“ oder jeder Interaktion basierend auf dem tatsächlichen Ausgang und dem erwarteten Ergebnis kontinuierlich angepasst werden. Dieser Prozess ermöglicht es, eine laufende und dynamische Einschätzung der relativen Fähigkeiten der Teilnehmer zu erhalten, was besonders nützlich in Bereichen ist, in denen ständig neue Teilnehmer hinzukommen oder die Leistungsfähigkeit sich rasch ändert, wie im Fall der LLMs.
Nachteilig kann natürlich sein, dass diese Art der Bewertung subjektiv und beeinflusst sein kann. Der Vorteil bei den standardisierten Antwortprüfungen ist die Prüfung auf einen gemeinsamen und definierten Nenner.
Natürlich hat jede dieser Prüfungsmethoden (standardisiert oder ELO) ihren sehr sinnvollen Einsatzbereich.
Weiterführende Informationen:
Erklärung der Nutzung von ELO als Messmethode bei der Large Model Systems Organisation (LMSYS Org) – https://lmsys.org/blog/2023-05-03-arena/
Das aktuelle Leaderboard für den Bereich von LLMs der LMSYS Org ist hier einsehbar: https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard
Veröffentlichung: Elo Uncovered: Robustness and Best Practices in Language Model Evaluation: https://arxiv.org/abs/2311.17295
Allgemeiner Hinweis:
Dieser Text wurde durch die Zuhilfenahme von ChatGPT mitgeneriert, bzw. Fachbegriffe wurden durch einen GPT erklärt.